目录
1. 问题现象与触发场景
在基于 RabbitMQ 的任务队列系统中,开发者可能会出现以下一种或多种异常现象:
-
核心现象: -任务重复执行 一个本应只执行一次的长时任务,在成功执行后,被另一个消费者(Worker)再次获取并执行。
-
关联日志表现
- 业务逻辑: 从业务日志看,第一个 Worker 可能已经完整地执行了所有业务逻辑。
-
系统级影响
- 资源浪费: 重复执行无谓地消耗了 CPU、内存和 I/O 资源。
- 数据一致性破坏: 对于非幂等任务(如“给用户账户增加100元”),重复执行将直接导致数据状态错误。
- 外部系统调用混乱: 重复向用户发送邮件、短信,或重复调用第三方支付接口。
典型触发场景:
此问题专属于执行时间超过特定阈值(默认为 15 或 30 分钟)的任务。常见场景包括:
- 数据密集型处理: 生成复杂的财务报表、执行大规模数据清洗或 ETL 流程。
- 媒体处理: 视频转码、高清图片处理、音频分析等。
- 机器学习任务: 模型训练或批处理推理。
- 长时间等待的 I/O 操作: 调用一个响应缓慢的第三方 API、等待大文件在不同系统间传输完成。
2. 根源解析:Broker 与 Worker 的“失信”危机
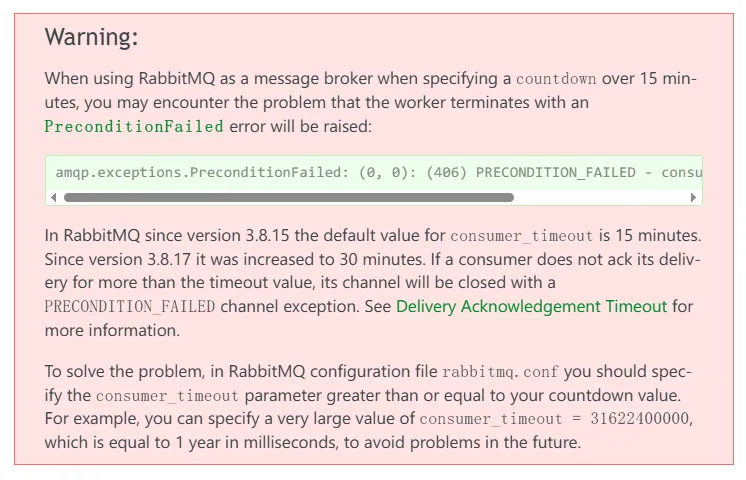
问题的根源是 RabbitMQ Broker 与长时间“沉默”的消费者之间因配置不当而产生的信任中断。其核心机制是 consumer_timeout。
2.1 什么是 consumer_timeout ?
consumer_timeout 是 RabbitMQ Broker 的一个关键配置项,它本质上是一个应用级别的健康检查计时器。
- 设计目的: 用于检测并清理那些已断开 TCP 连接但未正常关闭 AMQP 通道的“僵尸消费者”,防止消息被其永久持有而无法被处理。
- 工作原理: Broker 向一个消费者投递消息后,会启动一个计时器。如果 Broker 在
consumer_timeout指定的时间内(单位:毫秒)没有收到来自该消费者的任何确认(ACK),它会单方面判定该消费者已“死亡”。 - 默认值演变: 根据 Celery 官方文档 的说明,这个默认值随 RabbitMQ 版本而变化,这也是导致不同环境下行为不一的原因:
- RabbitMQ >= 3.8.17: 默认值为
1800000毫秒 (30 分钟)。 - RabbitMQ >= 3.8.15: 默认值为
900000毫秒 (15 分钟)。
- RabbitMQ >= 3.8.17: 默认值为
2.2 问题发生的全过程
下面的序列图清晰地展示了 Broker 与两个 Worker 之间的交互过程:
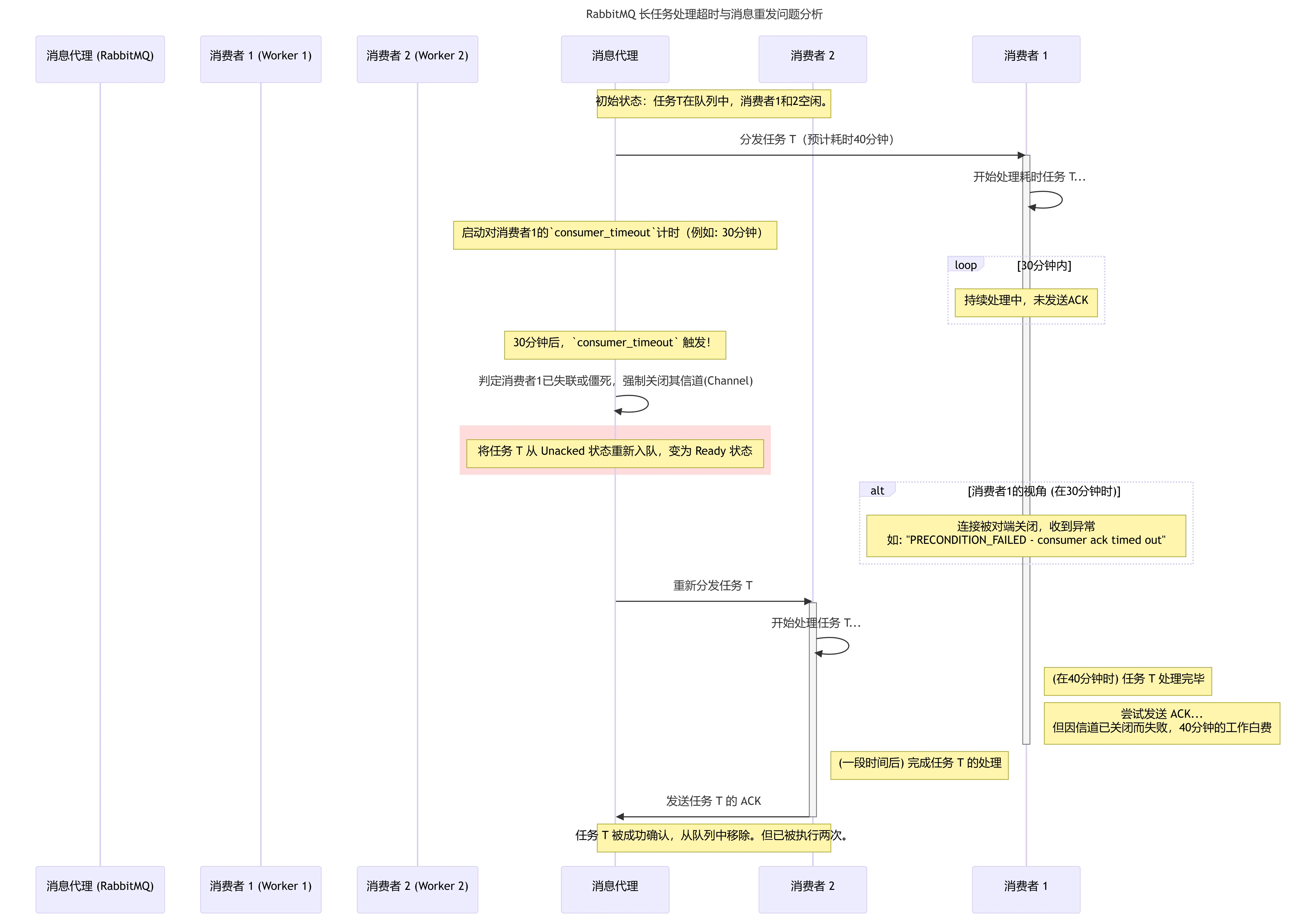
过程分解:
- 分发与计时: Broker 将耗时40分钟的任务 T 分发给 Worker 1,并启动一个30分钟的
consumer_timeout计时器。 - 超时判定: 在任务执行到第30分钟时,Worker 1 仍未完成任务,因此没有发送 ACK. Broker 的计时器超时。
- Broker 动作: Broker 判定 Worker 1 失联,执行两个动作: a. 强制关闭与 Worker 1 的 AMQP 通道。 b. 将任务 T 从 "unacked" 状态重新放回队列头部,变为 "ready" 状态。
- Worker 1 状态: Worker 1 的 AMQP 客户端库检测到通道被远端关闭,记录
PRECONDITION_FAILED异常。 - 任务重发: Broker 立即将处于 "ready" 状态的任务 T 分发给当时空闲的 Worker 2。
- 最终结果: 任务 T 被两个 Worker 执行,而 Worker 1 在完成工作后发送 ACK 的尝试会因为通道已关闭而失败。
一个常见的误解:TCP Heartbeat
很多人会混淆 TCP 心跳(如 Celery 的 broker_heartbeat)和 consumer_timeout。
- TCP Heartbeat: 作用于 TCP 连接层,用于防止网络设备(如防火墙、NAT)因连接空闲而关闭 TCP 套接字。它能证明消费者的进程还活着。
consumer_timeout: 作用于 AMQP 应用层,用于检测消费者是否在处理消息。 即便心跳正常,只要长时间没有 ACK,consumer_timeout仍然会触发。
3. 标准化解决方案
解决此问题的唯一正确方法是,确保 consumer_timeout 的值大于你系统中任何任务可能的最长执行时间,并留出合理的安全边际。
推荐实践:在 Docker 中通过挂载配置文件进行修改
这种方法实现了配置与容器镜像的分离,是现代运维的最佳实践。
步骤 1:创建自定义配置文件
在你的项目宿主机目录创建一个 .conf 文件。使用较高的数字前缀(如 90-)确保它在 RabbitMQ 启动时最后被加载,从而覆盖默认配置。
文件路径: ./config/rabbitmq/90-custom.conf
文件内容:
ini# ./config/rabbitmq/90-custom.conf
## ----------------------------------------------------------------------------
## Custom Core Settings for Long-Running Tasks
##
## See: https://www.rabbitmq.com/docs/delivery-acknowledgements#consumer-timeout
## ----------------------------------------------------------------------------
# Set consumer timeout to 3,600,000 milliseconds (1 hour).
# This value should be greater than the longest possible task execution time in your system.
# The Celery documentation suggests a very large value like 1 year to avoid future issues.
# Example: 1 hour = 3600 seconds = 3600000 milliseconds
consumer_timeout = 3600000
步骤 2:在 docker-compose.yml 中挂载配置
yaml# docker-compose.yml
version: '3.8'
services:
rabbitmq:
image: rabbitmq:3.11-management # Use a specific version
container_name: my-rabbit
ports:
- "5672:5672"
- "15672:15672"
volumes:
# Mount the custom config file into the container's conf.d directory.
# This ensures our settings override the defaults.
- ./config/rabbitmq/90-custom.conf:/etc/rabbitmq/conf.d/90-custom.conf
environment:
- RABBITMQ_DEFAULT_USER=user
- RABBITMQ_DEFAULT_PASS=password
修改后,使用 docker-compose up -d --force-recreate 重启 RabbitMQ 服务使配置生效。
4. 验证与排错
部署新配置后,必须进行验证。
-
进入 RabbitMQ 容器:
bashdocker exec -it my-rabbit bash -
执行查询命令:
bashrabbitmqctl eval 'application:get_env(rabbit, consumer_timeout).' -
分析返回结果:
- 成功: 输出应为
{ok,3600000},表明配置已成功应用。 - 失败: 输出
undefined,表示配置未加载。请立即检查:volumes挂载路径是否正确无误。- 宿主机上
90-custom.conf文件是否存在且内容正确。 - 文件权限是否允许 Docker 进程读取。
- 成功: 输出应为

5. 结论与防御性设计
- 直接原因:
consumer_timeout值小于任务执行时长。 - 根本解决: 调整
consumer_timeout参数,使其大于最长任务执行时间。 - 最佳实践: 在 Docker 中使用卷挂载独立的、高优先级的配置文件。
然而,仅仅修复配置是不够的。一个健壮的分布式系统需要更深层次的防御。
终极防御:任务幂等性 (Idempotency)
幂等性是指一个操作无论执行一次还是多次,其产生的影响和结果都是相同的。即使因为未知的网络问题、Broker 故障或其他原因导致任务重复,幂等性设计也能保证系统状态的最终一致性。
实现幂等性的策略:
- 唯一ID检查: 在任务开始时,检查一个唯一的事务ID或任务ID是否已被处理过。
- 版本号/状态机: 使用乐观锁(版本号)或严格的状态迁移来确保操作不会被错误地重复执行。
- 数据库唯一约束: 利用数据库的
UNIQUE约束来防止重复记录的插入。
本文作者:Silon汐冷
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!